diff-diff Plotting Functions: Current State & Improvement Roadmap
Goal: Explore the existing plotting capabilities of diff-diff and identify gaps relative to R’s ggfixest. The end goal is to contribute Python plotting functions that are as polished and flexible as ggfixest.
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport matplotlib.ticker as mtickerfrom diff_diff import ( DifferenceInDifferences, TwoWayFixedEffects, MultiPeriodDiD, CallawaySantAnna, SyntheticDiD, ImputationDiD, SunAbraham, generate_did_data, load_mpdta, plot_event_study, plot_group_effects,)import warningswarnings.filterwarnings('ignore')print('diff-diff imported successfully')
c:\Users\danny\anaconda3\Lib\site-packages\pandas\core\computation\expressions.py:22: UserWarning: Pandas requires version '2.10.2' or newer of 'numexpr' (version '2.8.7' currently installed).
from pandas.core.computation.check import NUMEXPR_INSTALLED
c:\Users\danny\anaconda3\Lib\site-packages\pandas\core\arrays\masked.py:56: UserWarning: Pandas requires version '1.4.2' or newer of 'bottleneck' (version '1.3.7' currently installed).
from pandas.core import (
diff-diff imported successfully
1.1. Generate Panel Data
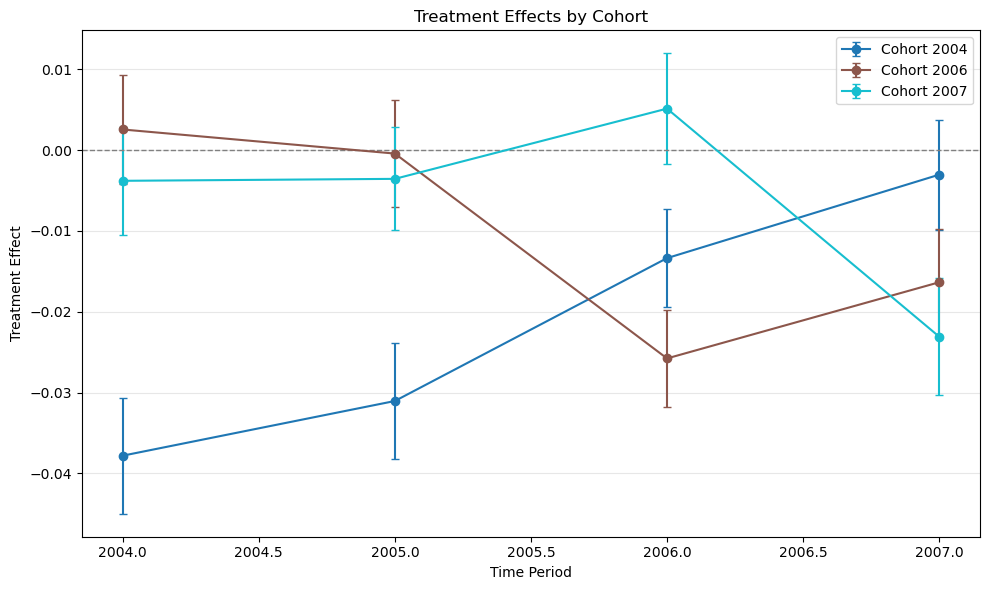
We use diff-diff’s built-in data generators plus the mpdta staggered adoption dataset.
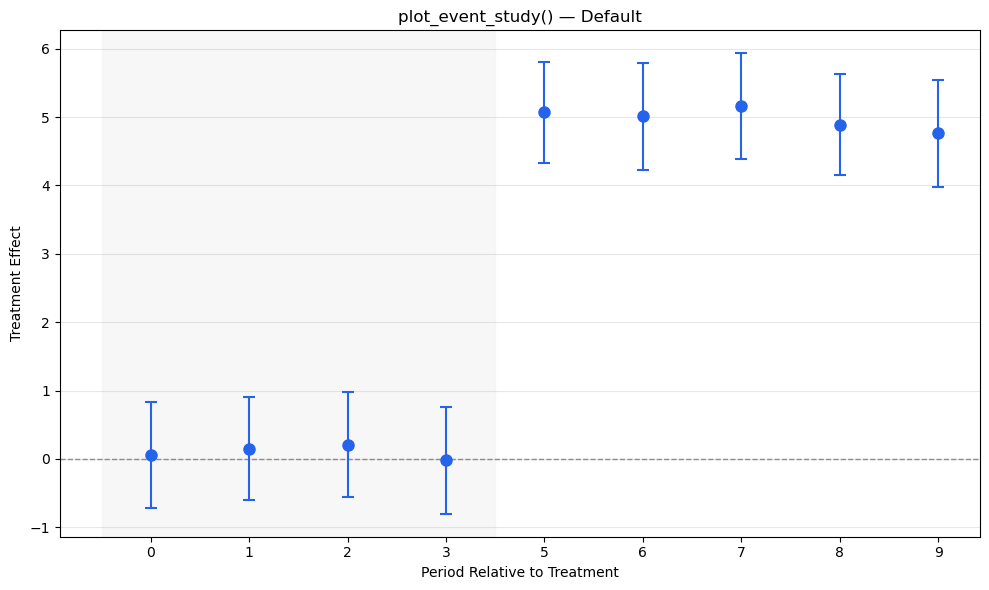
# Simple pre/post DiD datadata_simple = generate_did_data( n_units=200, n_periods=10, treatment_effect=5.0, treatment_fraction=0.5, treatment_period=5, seed=42)print(f"Simple DiD data: {data_simple.shape}")print(data_simple.head())
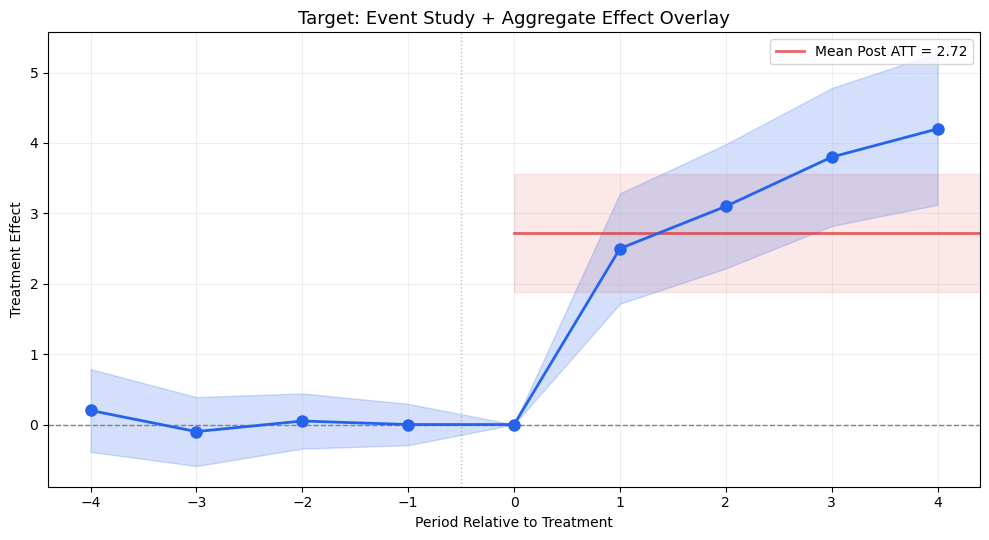
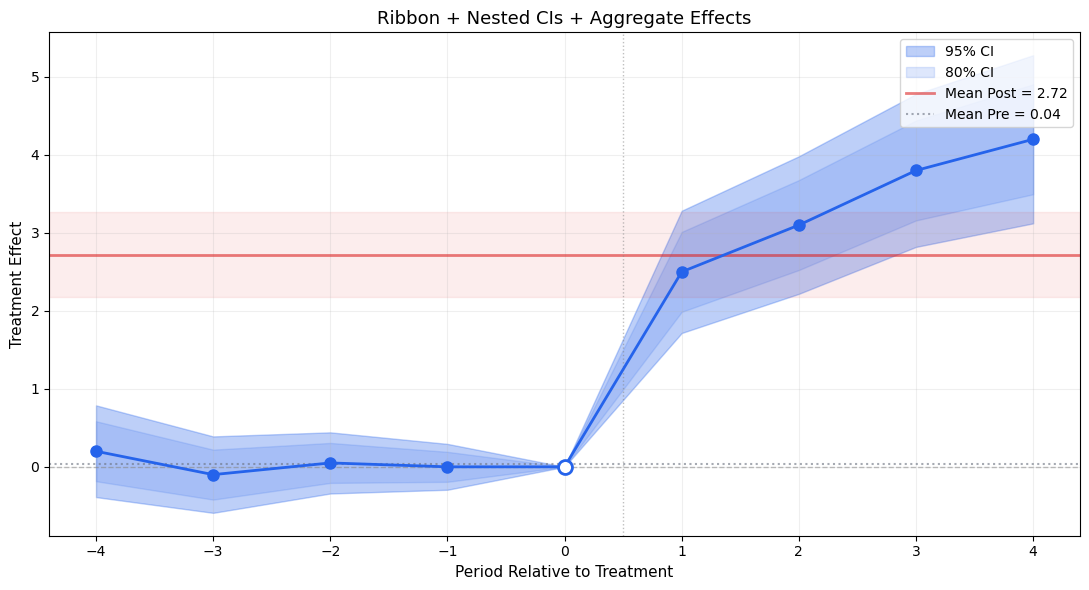
ggfixest’s aggr_eff = 'post' adds a shaded rectangle showing the mean post-treatment effect. Very useful for summarizing the overall ATT alongside the event study.
Below we prototype the key missing features as standalone functions. These could be contributed to diff-diff.
5.1. iplot_data() — Tidy Data Extraction
The foundation layer. Extracts a standardized DataFrame from any diff-diff result object, ready for custom plotting. This mirrors ggfixest’s iplot_data().
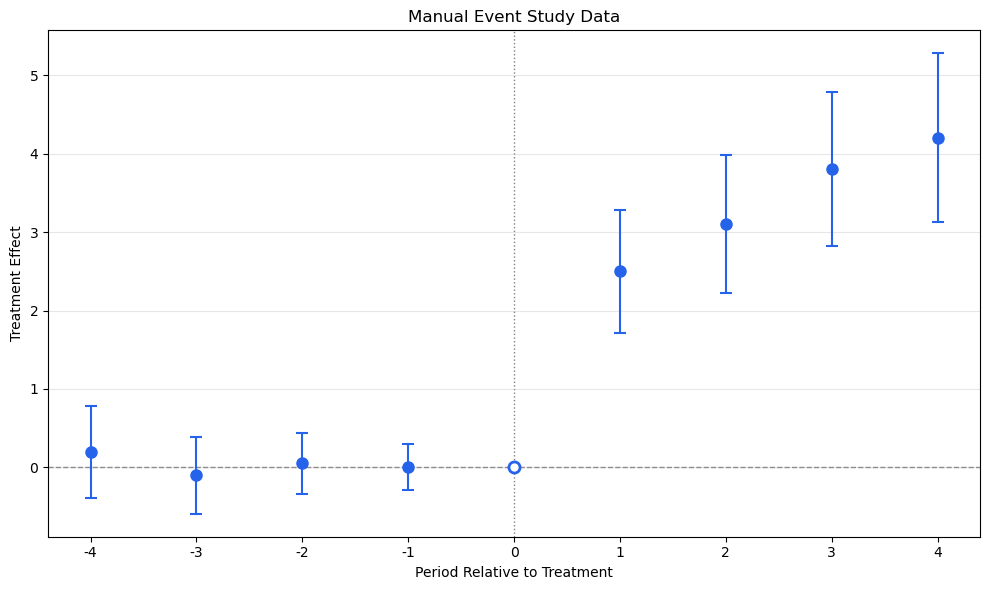
from scipy import stats as scipy_statsdef iplot_data(results, ci_level=0.95, reference_period=None):""" Extract tidy event study data from diff-diff results. Returns a DataFrame with columns: period, estimate, se, ci_low, ci_high, ci_level, is_ref """ z = scipy_stats.norm.ppf(1- (1- ci_level) /2)# Handle DataFrame inputifisinstance(results, pd.DataFrame): df = results.copy()if'period'notin df.columns:raiseValueError("DataFrame must have 'period' column")if'effect'in df.columns: df = df.rename(columns={'effect': 'estimate'}) df['ci_low'] = df['estimate'] - z * df['se'] df['ci_high'] = df['estimate'] + z * df['se'] df['ci_level'] = ci_level df['is_ref'] = df['period'] == reference_period if reference_period isnotNoneelseFalsereturn df[['period', 'estimate', 'se', 'ci_low', 'ci_high', 'ci_level', 'is_ref']]# Handle dict inputifisinstance(results, dict) and'effects'in results: periods =sorted(results['effects'].keys()) rows = []for p in periods: est = results['effects'][p] se_val = results.get('se', {}).get(p, 0) rows.append({'period': p, 'estimate': est, 'se': se_val,'ci_low': est - z * se_val, 'ci_high': est + z * se_val,'ci_level': ci_level,'is_ref': p == reference_period if reference_period isnotNoneelseFalse, })return pd.DataFrame(rows)# Handle diff-diff result objects# Try extracting event_study_effects (CallawaySantAnna, etc.)ifhasattr(results, 'event_study_effects'): es = results.event_study_effects rows = []for entry in es: p = entry.get('event_time', entry.get('period', 0)) est = entry.get('att', entry.get('estimate', 0)) se_val = entry.get('se', 0) rows.append({'period': p, 'estimate': est, 'se': se_val,'ci_low': est - z * se_val, 'ci_high': est + z * se_val,'ci_level': ci_level,'is_ref': p == reference_period if reference_period isnotNoneelseFalse, })return pd.DataFrame(rows).sort_values('period').reset_index(drop=True)raiseTypeError(f"Unsupported result type: {type(results)}")# Demotidy = iplot_data(es_df, ci_level=0.95, reference_period=0)print("Tidy event study data:")tidy
Tidy event study data:
period
estimate
se
ci_low
ci_high
ci_level
is_ref
0
-4
0.20
0.30
-0.387989
0.787989
0.95
False
1
-3
-0.10
0.25
-0.589991
0.389991
0.95
False
2
-2
0.05
0.20
-0.341993
0.441993
0.95
False
3
-1
0.00
0.15
-0.293995
0.293995
0.95
False
4
0
0.00
0.00
0.000000
0.000000
0.95
True
5
1
2.50
0.40
1.716014
3.283986
0.95
False
6
2
3.10
0.45
2.218016
3.981984
0.95
False
7
3
3.80
0.50
2.820018
4.779982
0.95
False
8
4
4.20
0.55
3.122020
5.277980
0.95
False
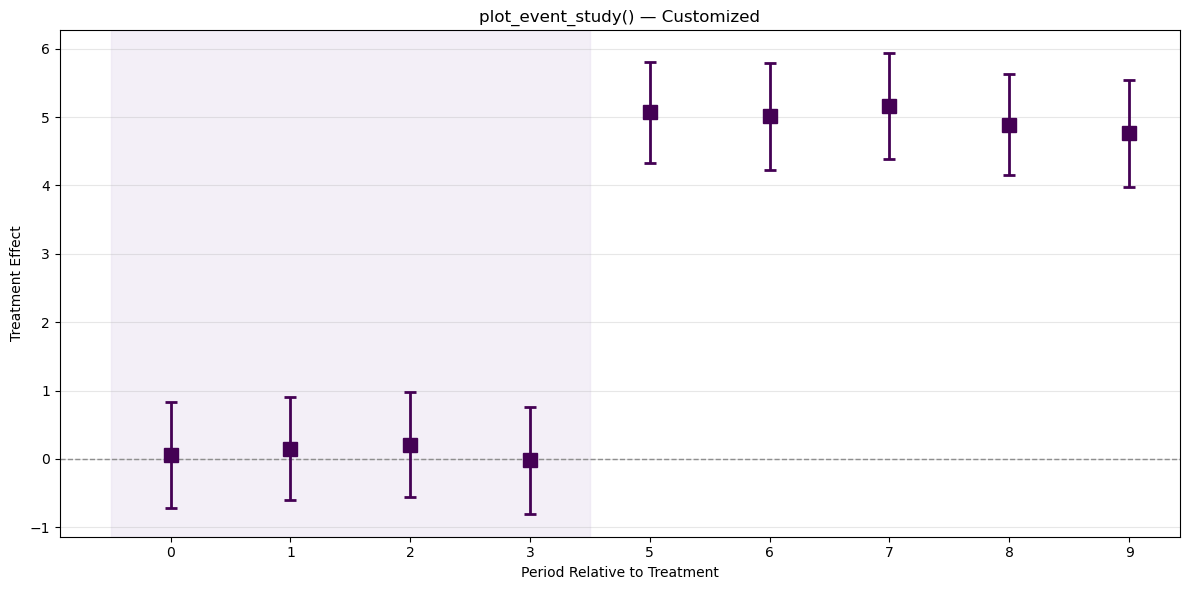
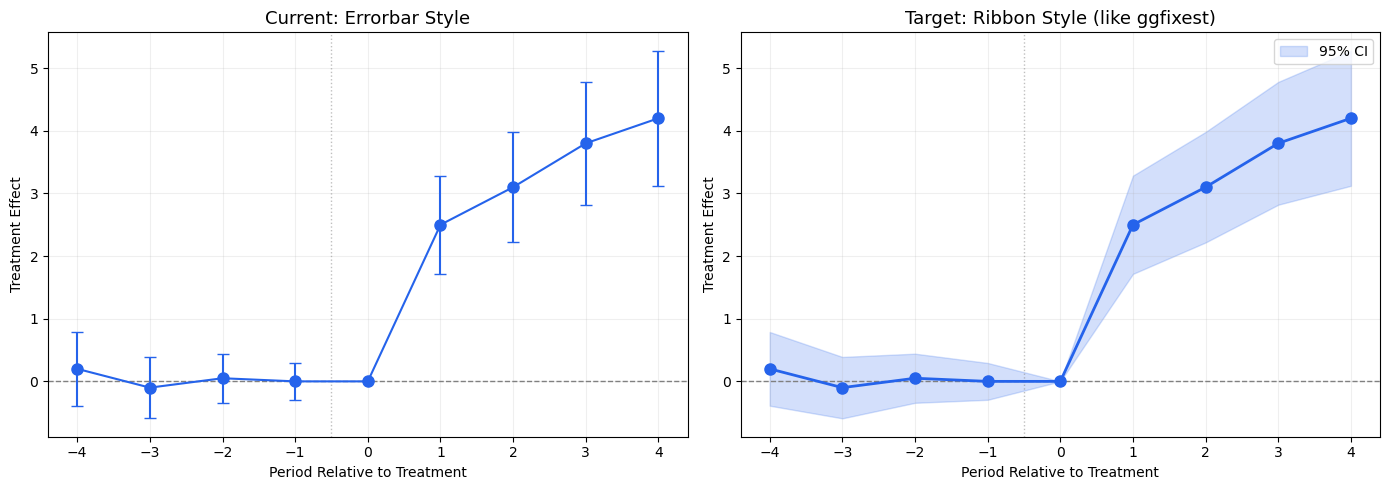
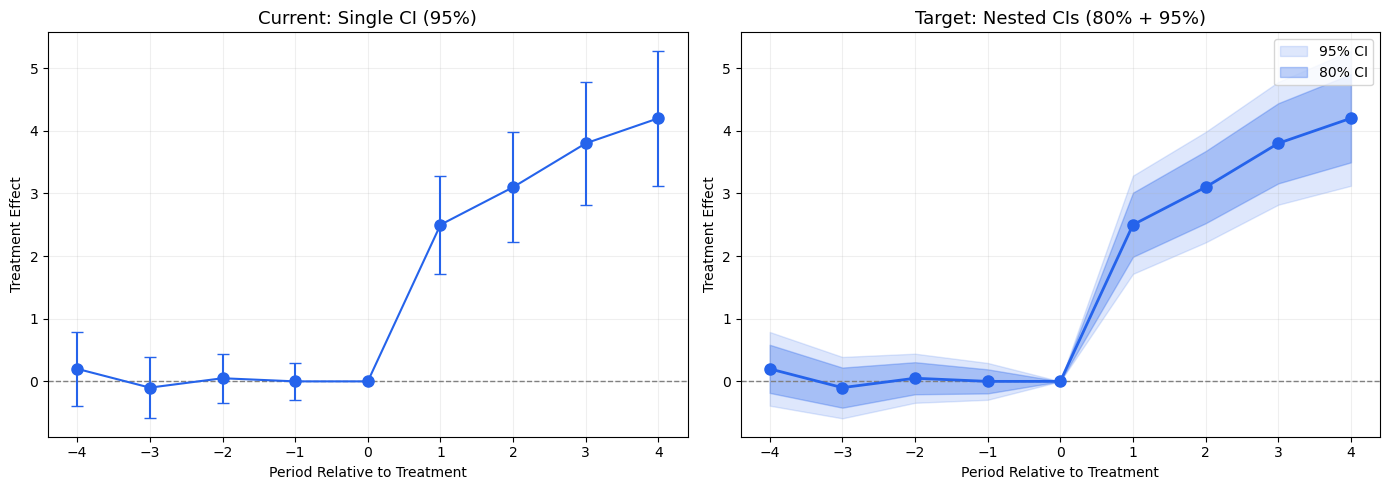
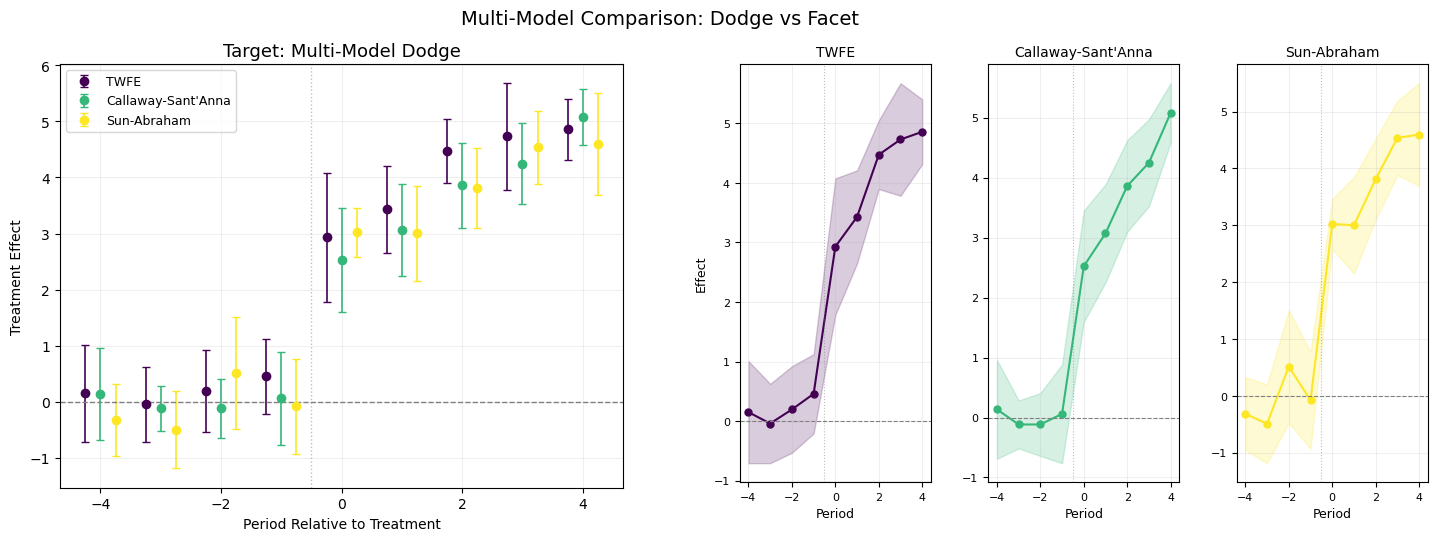
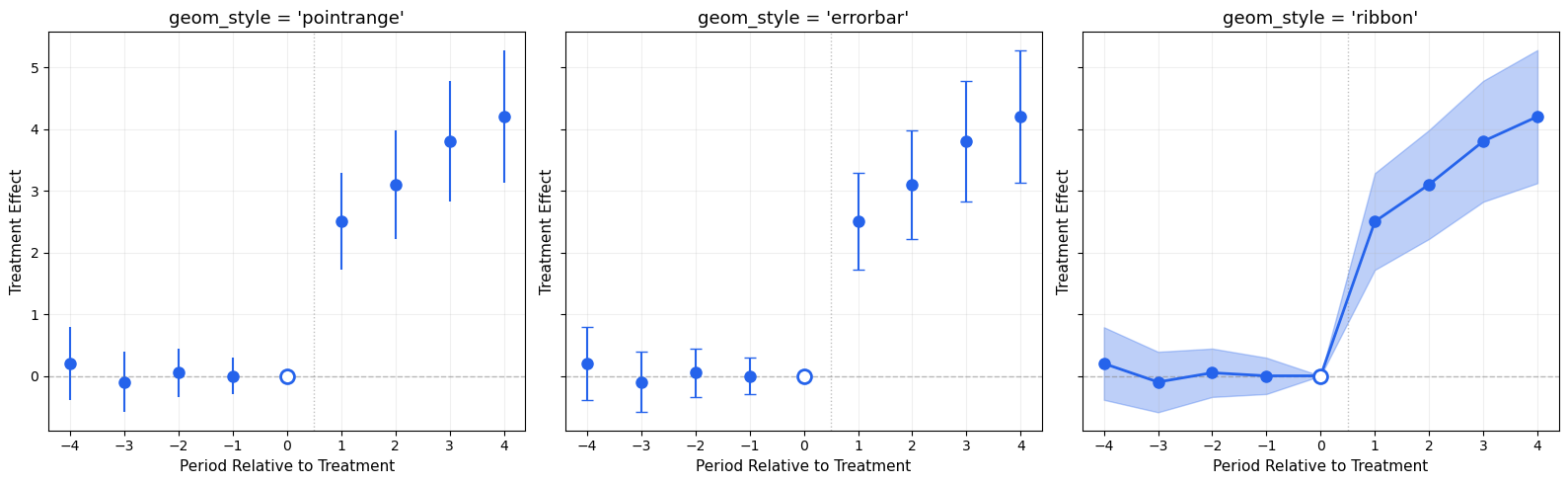
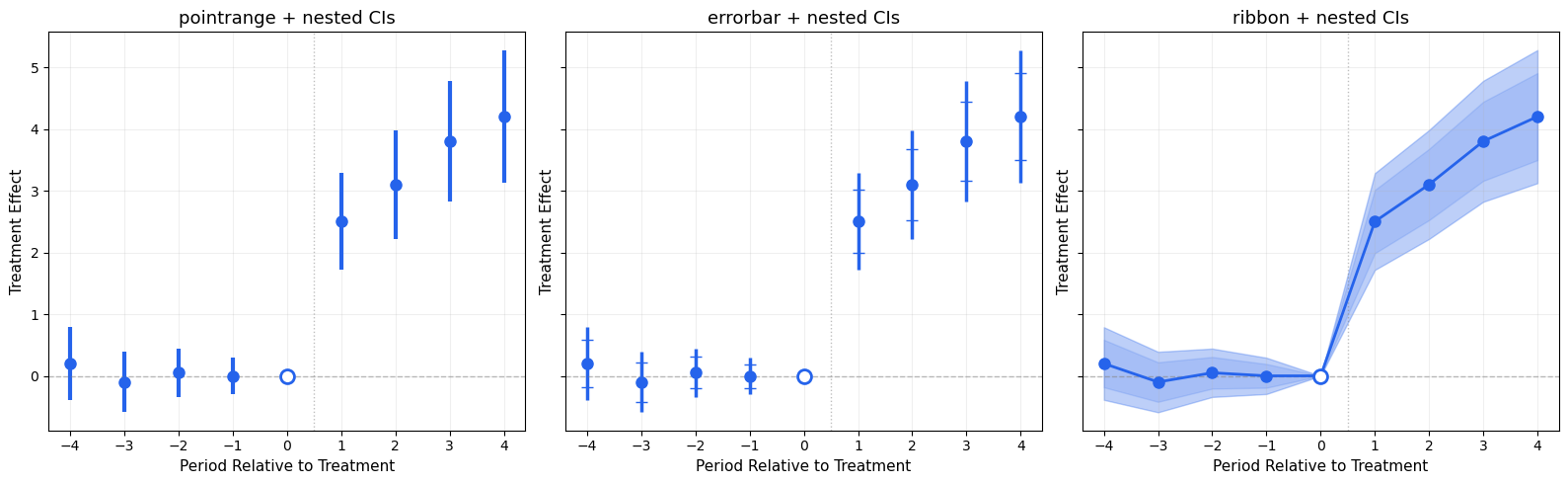
5.2. ggiplot() — Enhanced Event Study Plot
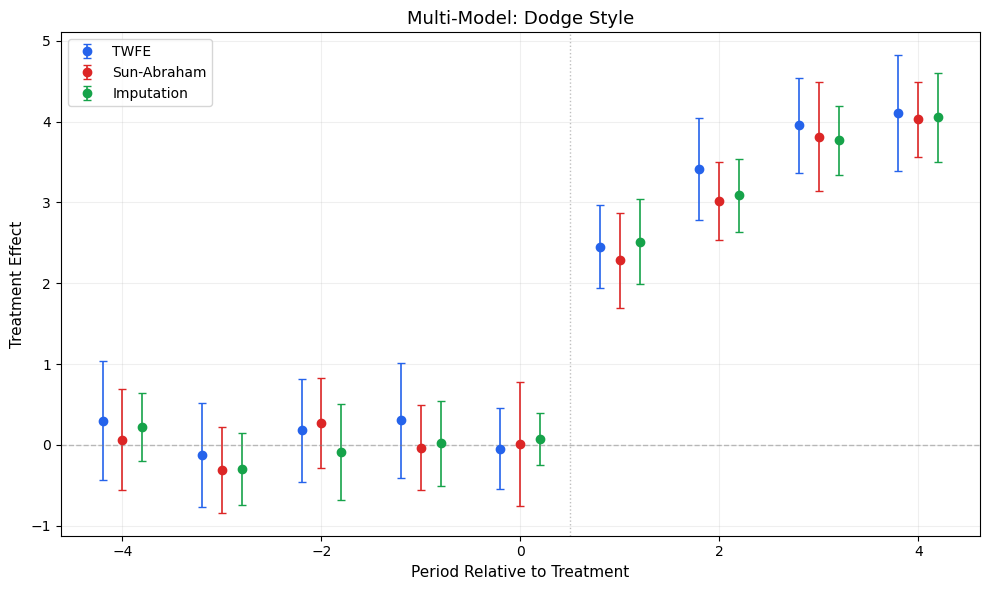
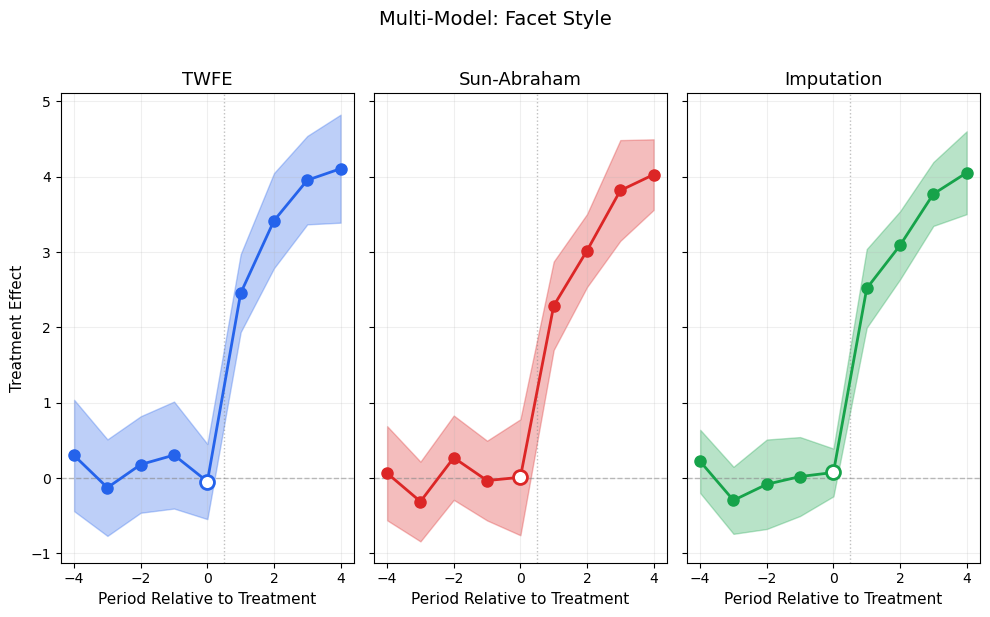
The main function, inspired by ggfixest::ggiplot(). Supports ribbon CIs, multiple CI levels, multi-model comparison, and aggregate effects overlay.
def ggiplot( results,*, geom_style='pointrange', # 'pointrange', 'errorbar', 'ribbon' ci_level=0.95, # float or list of floats for nested CIs reference_period=None, aggr_eff=None, # 'post', 'pre', 'both'# Multi-model: pass dict {name: results} multi_style='dodge', # 'dodge' or 'facet'# Aesthetics colors=None, figsize=(10, 6), title='Event Study', xlabel='Period Relative to Treatment', ylabel='Treatment Effect', show_zero=True, show_ref_line=True, shade_pre=False, ax=None, show=True,):""" Enhanced event study plot inspired by ggfixest::ggiplot(). Parameters ---------- results : DataFrame, dict of DataFrames, or diff-diff result object If dict, keys are model names and values are result objects (multi-model). geom_style : str 'pointrange' (default), 'errorbar', or 'ribbon' ci_level : float or list of float Confidence level(s). Pass [0.80, 0.95] for nested CIs. aggr_eff : str or None 'post' to overlay mean post-treatment effect, 'pre' for pre, 'both' for both. multi_style : str 'dodge' (side-by-side) or 'facet' (separate panels). """ default_colors = ['#2563eb', '#dc2626', '#16a34a', '#ea580c', '#8b5cf6']if colors isNone: colors = default_colors# Normalize ci_level to listifisinstance(ci_level, (int, float)): ci_levels = [ci_level]else: ci_levels =sorted(ci_level, reverse=True) # widest first# Handle multi-model dict input is_multi =isinstance(results, dict) andnot ('effects'in results)if is_multi and multi_style =='facet': n_models =len(results) fig, axes_arr = plt.subplots(1, n_models, figsize=(figsize[0], figsize[1]), sharey=True)if n_models ==1: axes_arr = [axes_arr]for idx, (name, res) inenumerate(results.items()): ggiplot( res, geom_style=geom_style, ci_level=ci_level, reference_period=reference_period, aggr_eff=aggr_eff, colors=[colors[idx %len(colors)]], title=name, xlabel=xlabel, ylabel=ylabel if idx ==0else'', show_zero=show_zero, show_ref_line=show_ref_line, ax=axes_arr[idx], show=False, ) fig.suptitle(title, fontsize=14, y=1.02) plt.tight_layout()if show: plt.show()return axes_arr# Single model or dodgeif ax isNone: fig, ax = plt.subplots(figsize=figsize)if is_multi:# Dodge: plot all models on same axis with offset model_names =list(results.keys()) n_models =len(model_names) dodge_width =0.2for idx, (name, res) inenumerate(results.items()): tidy = iplot_data(res, ci_level=ci_levels[-1], reference_period=reference_period) offset = (idx - (n_models -1) /2) * dodge_width color = colors[idx %len(colors)] x = tidy['period'].values + offsetif geom_style =='ribbon':for cl in ci_levels: td = iplot_data(res, ci_level=cl, reference_period=reference_period) alpha_fill =0.15+0.15* (1- ci_levels.index(cl) /max(1, len(ci_levels) -1)) ax.fill_between(td['period'].values + offset, td['ci_low'], td['ci_high'], alpha=alpha_fill, color=color) ax.plot(x, tidy['estimate'], 'o-', color=color, markersize=6, linewidth=1.5, label=name, zorder=3)elif geom_style =='errorbar': ax.errorbar(x, tidy['estimate'], yerr=[tidy['estimate'] - tidy['ci_low'], tidy['ci_high'] - tidy['estimate']], fmt='o', color=color, capsize=3, markersize=6, linewidth=1.2, label=name)else: # pointrange ax.errorbar(x, tidy['estimate'], yerr=[tidy['estimate'] - tidy['ci_low'], tidy['ci_high'] - tidy['estimate']], fmt='o', color=color, capsize=0, markersize=6, linewidth=2, label=name) ax.legend(fontsize=10)else:# Single model color = colors[0]# Get tidy data for the widest CI level tidy = iplot_data(results, ci_level=ci_levels[-1], reference_period=reference_period) x = tidy['period'].valuesif geom_style =='ribbon':for cl in ci_levels: td = iplot_data(results, ci_level=cl, reference_period=reference_period) alpha_fill =0.15+0.15* (1- ci_levels.index(cl) /max(1, len(ci_levels) -1)) label =f'{cl:.0%} CI'iflen(ci_levels) >1elsef'{cl:.0%} CI' ax.fill_between(x, td['ci_low'], td['ci_high'], alpha=alpha_fill, color=color, label=label) ax.plot(x, tidy['estimate'], 'o-', color=color, markersize=8, linewidth=2, zorder=3)elif geom_style =='errorbar':for cl in ci_levels: td = iplot_data(results, ci_level=cl, reference_period=reference_period) lw =1.5if cl == ci_levels[-1] else2.5 cs =4if cl == ci_levels[-1] else0 label =f'{cl:.0%} CI' ax.errorbar(x, td['estimate'], yerr=[td['estimate'] - td['ci_low'], td['ci_high'] - td['estimate']], fmt='o'if cl == ci_levels[-1] else'none', color=color, capsize=cs, markersize=8, linewidth=lw, label=label, zorder=2+ ci_levels.index(cl))else: # pointrangefor cl in ci_levels: td = iplot_data(results, ci_level=cl, reference_period=reference_period) lw =1.5if cl == ci_levels[-1] else3 ax.errorbar(x, td['estimate'], yerr=[td['estimate'] - td['ci_low'], td['ci_high'] - td['estimate']], fmt='o'if cl == ci_levels[-1] else'none', color=color, capsize=0, markersize=8, linewidth=lw, zorder=2+ ci_levels.index(cl))# Reference period markerif reference_period isnotNone: ref_row = tidy[tidy['period'] == reference_period]iflen(ref_row) >0: ax.plot(reference_period, ref_row['estimate'].values[0],'o', color='white', markersize=10, markeredgecolor=color, markeredgewidth=2, zorder=5)# Aggregate effect overlayif aggr_eff isnotNone: tidy_agg = iplot_data(results, ci_level=ci_levels[-1], reference_period=reference_period)if aggr_eff in ('post', 'both'): post = tidy_agg[tidy_agg['period'] > (reference_period or-0.5)]iflen(post) >0: mean_eff = post['estimate'].mean() mean_se = np.sqrt(np.mean(post['se']**2)) z_val = scipy_stats.norm.ppf(1- (1- ci_levels[-1]) /2) ax.axhspan(mean_eff - z_val*mean_se, mean_eff + z_val*mean_se, alpha=0.08, color='#dc2626') ax.axhline(mean_eff, color='#dc2626', linewidth=2, alpha=0.6, label=f'Mean Post = {mean_eff:.2f}')if aggr_eff in ('pre', 'both'): pre = tidy_agg[tidy_agg['period'] < (reference_period or0)]iflen(pre) >0: mean_eff = pre['estimate'].mean() ax.axhline(mean_eff, color='#6b7280', linewidth=1.5, linestyle=':', alpha=0.6, label=f'Mean Pre = {mean_eff:.2f}') ax.legend(fontsize=10)# Reference linesif show_zero: ax.axhline(0, color='gray', linestyle='--', linewidth=1, alpha=0.5)if show_ref_line and reference_period isnotNone: ax.axvline(reference_period +0.5, color='gray', linestyle=':', linewidth=1, alpha=0.5) ax.set_title(title, fontsize=13) ax.set_xlabel(xlabel, fontsize=11) ax.set_ylabel(ylabel, fontsize=11) ax.grid(True, alpha=0.2)if show: plt.tight_layout() plt.show()return axprint('ggiplot() defined')